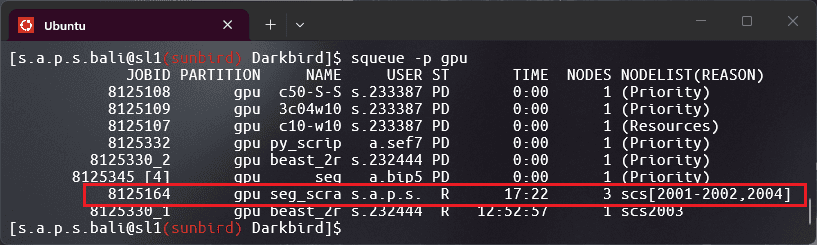
Multi-Node Distributed Training on HPC
I've been working on synthetic voice generation models for Welsh recently, and these experiments were actually done early on when I first got access to the HPC cluster. I needed to validate the multi-node distributed training setup before diving into the much longer TTS training runs, so I put together two quick demo experiments: image generation with diffusion models and face segmentation.
The A100 partition was completely booked (story of my life), so I grabbed what was available - three nodes on the V100 partition, each with two GPUs. Six V100s total, not bad. These simpler vision tasks demonstrate the core distributed training concepts without the complexity of speech synthesis, and serve as a reproducible testbed for the techniques I'm now applying to the voice models.
Fair warning: I wasn't optimizing these experiments since the goal was infrastructure validation, not state-of-the-art results. Learning rate schedules are aggressive, training curves show variance, and I didn't do extensive hyperparameter tuning. But the experiments confirmed the setup works, which is what mattered. Now I'm finally publishing the code and models after sitting on them for a while.
All the code is on GitHub if you want to poke around, and I uploaded the trained models to HuggingFace (DDPM here, segmentation here).
Setting the stage
The hardware setup was straightforward; PyTorch's DistributedDataParallel with NCCL backend across 3 nodes, 2 V100-16GB GPUs per node. SLURM handles all the job scheduling and node allocation, which means I just write a submission script and let the cluster figure out the rest.
I've written about the initial HPC setup in a previous post if you're interested in the gory details of getting SLURM and PyTorch to play nicely together.
Experiment 1 - Generating tiny images with diffusion
First up was a Denoising Diffusion Probabilistic Model (DDPM) on CIFAR-10. These models are conceptually elegant; you gradually add noise to images during training, then learn to reverse that process. During inference, you start with pure noise and progressively denoise it into a coherent image.
I used a U-Net architecture with 128 base channels (~34M parameters total) and trained for 100 epochs with 1000 diffusion timesteps. With a batch size of 64 per GPU, I got an effective batch size of 384 across all six GPUs.
The whole thing finished in about 47 minutes, which felt surprisingly fast. Final loss settled around 0.030. Here's what it generates:

The denoising process looks like this when you capture each timestep:

You can see it starting from complete noise and gradually resolving into recognizable objects - planes, cars, animals. Sometimes the details are fuzzy, but the overall structure is there. Not bad for a relatively small model trained on 32×32 images.
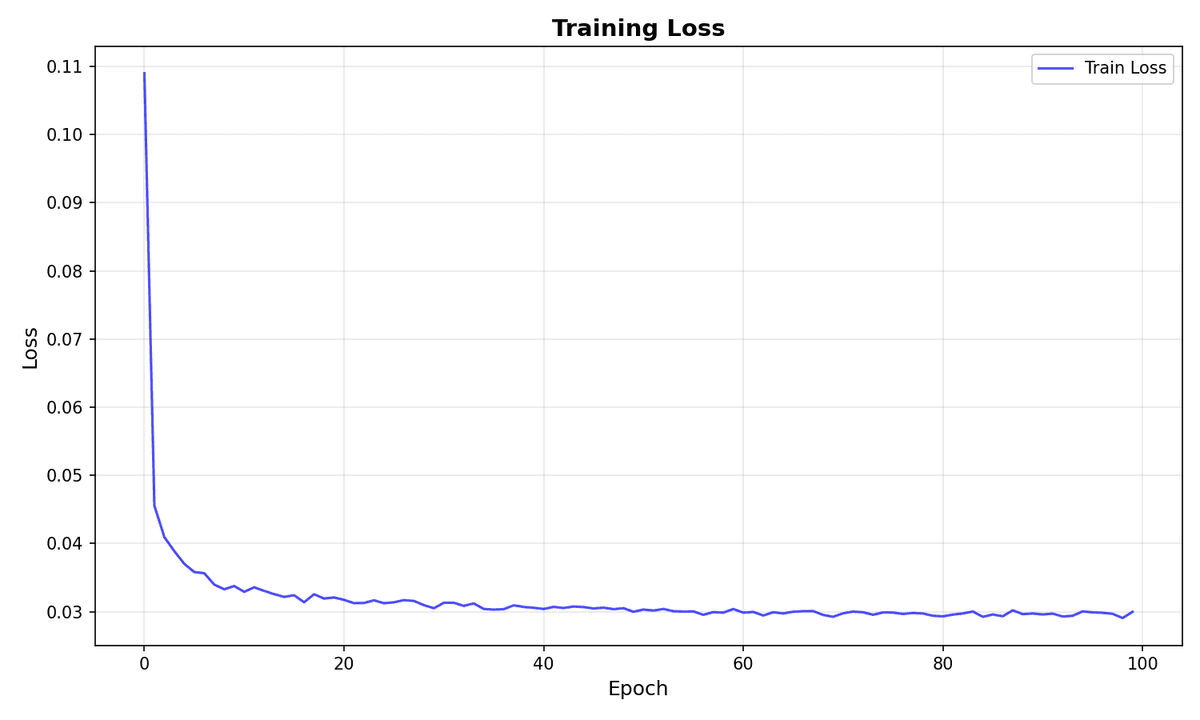
The loss curve is mostly smooth and trends downward consistently, with no weird synchronization spikes that would suggest issues with the distributed setup.
Experiment 2 - Parsing faces into pieces
For the second experiment, I wanted something more challenging; face segmentation on CelebAMask-HQ. This dataset has 30,000 celebrity face images with pixel-wise annotations for 19 different classes: skin, eyes, eyebrows, nose, mouth, hair, glasses, earrings, etc.
I used DeepLabV3+ with a ResNet-101 backbone (58M parameters), which is a pretty standard choice for semantic segmentation. The model outputs a 19-channel prediction map, and each pixel gets classified into one of those face parts.
Here's where it got interesting, I ran two versions -
Pretrained - Started with ImageNet/COCO weights and fine-tuned for 100 epochs. This is the "standard" approach you'd use in production.
From Scratch - Random initialization, trained for 200 epochs with a higher learning rate. This is more of a "can we even do this?" curiosity.
The dataset split was 27K training images and 3K validation images. I resized everything to 256×256 and used a batch size of 16 per GPU (96 effective across all GPUs).
Results
The pretrained model trained for ~1.7 hours and hit 72.72% mIoU with 95.06% pixel accuracy. Pretty solid.
The from-scratch model took longer (~3.4 hours for 200 epochs) but ended up with 75.36% mIoU and 94.78% pixel accuracy. Wait, what? The randomly initialized model actually performed better?
My theory: it got twice as many epochs and I cranked up the learning rate since there were no pretrained weights to preserve. More optimization time and a more aggressive learning schedule probably let it converge to a better solution, even without the ImageNet head start.
Here's a visual comparison across the same test image:

Both models do a decent job overall. If you look at the boundaries, the pretrained model actually produces much more accurate boundaries despite the lower mIoU score. The from-scratch model's higher mIoU might come from better performance on larger regions like skin and hair, while struggling more with fine details. It's also worth noting that neither model had seen these specific test images during training, they were held out for validation only.
Training curves show both models converging, though with interesting differences:

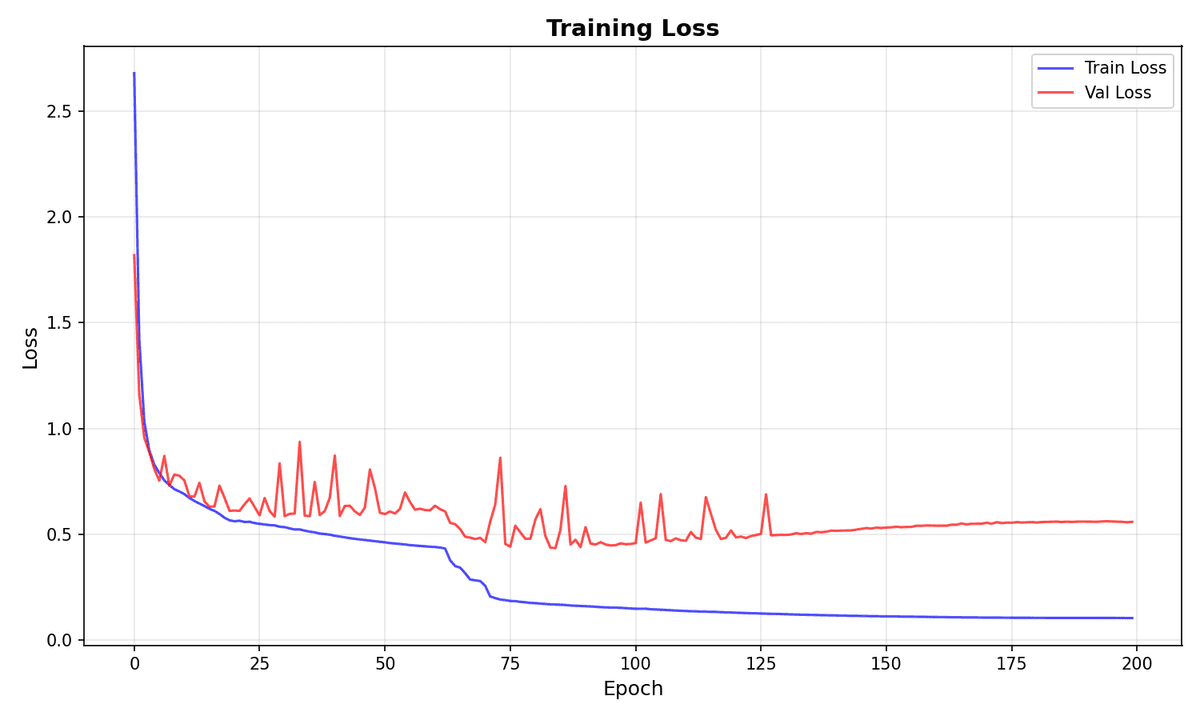
The training losses here are much smoother than the diffusion training. The pretrained model's validation loss is particularly clean, it climbs smoothly and shows early signs of overfitting around epoch 15. The from-scratch model tells a different story: validation loss is quite janky with significant spikes throughout training, and overfitting only becomes apparent around epoch 80.
The most interesting phenomenon is what happens at epoch 65 in the from-scratch training - the model hits a loss cliff, where the training loss abruptly drops in a staircase pattern. This suggests the optimizer escaped a local minimum and transitioned into a better basin of the loss landscape. These sharp transitions are relatively rare but indicate the model found a fundamentally better solution space.

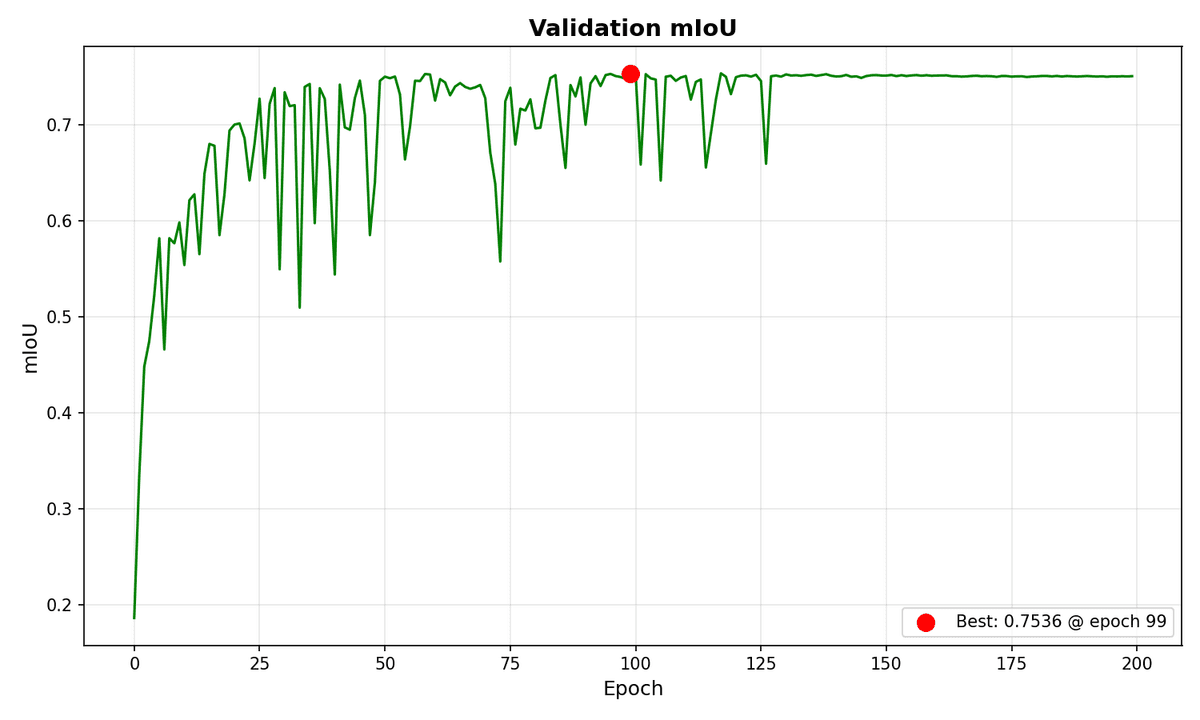
The mIoU curves reflect these training dynamics. The pretrained model has occasional spikes but they're few and far between; overall quite stable. The from-scratch model shows more aggressive spikes throughout, consistent with its janky validation loss.
The end
The main goal here was documenting the distributed training workflow for my Welsh voice generation project, and these experiments confirmed the setup works reliably. PyTorch's DDP handles most of the complexity, and SLURM takes care of resource allocation. The main gotcha is making sure your data loading doesn't become a bottleneck; with six GPUs reading from shared storage, I/O can get messy fast.
The pretrained vs. from-scratch result was unexpected but makes sense in hindsight. Transfer learning gives you a faster path to "good enough" results, but if you have the compute budget and time to train longer, starting from scratch with a more aggressive learning schedule can work just as well or better. Though again, I wasn't optimizing, you can see the variance in those training curves. With proper tuning, both approaches would likely converge more smoothly.
After I validated the infrastructure, I applied these same patterns to the TTS models with more confidence. The Welsh voice synthesis work involved much larger models and longer training runs, so having this baseline proof that the multi-node setup scales correctly was reassuring.
Resources
If you want to replicate these experiments -
- Code - GitHub - Darkbird
- DDPM Model - HuggingFace - DDPM
- Segmentation Models - HuggingFace - Deeplabv3+
- HPC Setup Guide - Previous Post